Here: https://github.com/richgel999/lzham_codec
I haven't merged over the XCode project yet, but it's fully compatible with OSX now. Also, LZHAM v1.0 is not backwards compatible with the previous alpha version.
Sunday, January 25, 2015
Saturday, January 24, 2015
Windows 10: An Arrow Aimed Straight at Steam
I find this very interesting news, and if you're not paying attention you should:
Phoronix: Windows 10 To Be A Free Upgrade: What Linux Users Need To Know
PC World: Windows 10's new features: Cortana, a 'Spartan' browser, Xbox streaming, and more
Rock, Paper, Shotgun: Is Windows 10 Good For PC Gamers Or XBone Owners?
I think Microsoft's strategy here is surprisingly well thought out. Their execs finally figured out "to know your enemy you must become your enemy". Windows 10 is free, has a new state of the art graphics API (DirectX v12) created by the best graphics specialists, real software engineers, and real testers in the business, awesome developer tools (Visual Studio) that actually work with real CPU/GPU debugging and profiling support all built in, all of your existing apps and games still work, and they're pulling out all the stops with the Halo/Xbox branding right down into the OS and browser.
They just need to make the Windows 10 App Store not suck: Continue to use their Xbox brand as a lever, carefully feed and nourish the ecosystem, listen to their customers, and undercut the living hell out of Steam. Steam itself started out as a total pile of crap, but they listened to their customers, fixed the problems over time, gave their customers good deals and shipped apps you couldn't get anywhere else at the right prices, and built and nourished the community. Microsoft can do all the same things, and perhaps they've finally figured this out.
It's now all down to execution, recovering from some obviously bone headed moves (sometimes fueled by excessive Redmond Kool-Aid drinking, like the botched Windows 8 UI and no Start Menu disasters), recognizing and quickly recovering from the inevitable new bone headed moves, and sustaining the effort over the long term (something Microsoft has definitely not been very good at except for their core brands). Competition is great.
Phoronix: Windows 10 To Be A Free Upgrade: What Linux Users Need To Know
PC World: Windows 10's new features: Cortana, a 'Spartan' browser, Xbox streaming, and more
Rock, Paper, Shotgun: Is Windows 10 Good For PC Gamers Or XBone Owners?
I think Microsoft's strategy here is surprisingly well thought out. Their execs finally figured out "to know your enemy you must become your enemy". Windows 10 is free, has a new state of the art graphics API (DirectX v12) created by the best graphics specialists, real software engineers, and real testers in the business, awesome developer tools (Visual Studio) that actually work with real CPU/GPU debugging and profiling support all built in, all of your existing apps and games still work, and they're pulling out all the stops with the Halo/Xbox branding right down into the OS and browser.
They just need to make the Windows 10 App Store not suck: Continue to use their Xbox brand as a lever, carefully feed and nourish the ecosystem, listen to their customers, and undercut the living hell out of Steam. Steam itself started out as a total pile of crap, but they listened to their customers, fixed the problems over time, gave their customers good deals and shipped apps you couldn't get anywhere else at the right prices, and built and nourished the community. Microsoft can do all the same things, and perhaps they've finally figured this out.
It's now all down to execution, recovering from some obviously bone headed moves (sometimes fueled by excessive Redmond Kool-Aid drinking, like the botched Windows 8 UI and no Start Menu disasters), recognizing and quickly recovering from the inevitable new bone headed moves, and sustaining the effort over the long term (something Microsoft has definitely not been very good at except for their core brands). Competition is great.
Friday, January 23, 2015
LZHAM v1.0 is being tested on iOS/OSX/Linux/Win
Currently testing it on a few machines using random codec settings with ~3.5 million files. We also just switched over our title's bundle decompression step from LZMA to LZHAM, so the decompressor will be tested on many iOS devices too.
I've also tested the compression portion of the code on iOS, but I won't be able to get much coverage there before releasing it. Honestly the decompressor is much more interesting for mobile devices (that's really the whole point of LZHAM).
I'll be porting and testing LZHAM on Android within a week or so - should be easy by this point.
I've also tested the compression portion of the code on iOS, but I won't be able to get much coverage there before releasing it. Honestly the decompressor is much more interesting for mobile devices (that's really the whole point of LZHAM).
I'll be porting and testing LZHAM on Android within a week or so - should be easy by this point.
LZHAM v1.0 vs. LZMA decompression perf. on iPhone 6+
I borrowed a coworker's iPhone 6+ and reran my bundle compression benchmarking app. According to wikipedia, it's a 1.4 GHz dual-core ARMv8-A.
LZHAM is 2.3x-9x faster on this device, unless the bundle's compressed size is < 1000 bytes. The comp size threshold where LZHAM is faster is lower than what I'm used to seeing, not sure exactly why yet.
1. Bundles sorted by LZHAM vs. LZMA decompression speedup (slowest on left):

2. Bundles sorted by LZMA compressed size (smallest on left), with relative decompression speedup in blue:

LZHAM is 2.3x-9x faster on this device, unless the bundle's compressed size is < 1000 bytes. The comp size threshold where LZHAM is faster is lower than what I'm used to seeing, not sure exactly why yet.
1. Bundles sorted by LZHAM vs. LZMA decompression speedup (slowest on left):
2. Bundles sorted by LZMA compressed size (smallest on left), with relative decompression speedup in blue:
Wednesday, January 21, 2015
First LZHAM iOS stats with Unity asset bundle data
Got everything (both the compressor and decompressor) working. Was surprisingly easy. Had 1 misaligned load to deal with in the compressor's match finder because of a #ifdef problem.
I combined together 3 of our larger Unity asset bundles together into a single .TAR file and here are the current results on my iPhone 4 (800 MHz A4 CPU - 512MB RAM):
For compression, I used a 16MB dictionary, highest compression (level 4) with normal parsing. Compression is slow, but LZHAM is designed for offline use so as long as it works at all I'm not sweating it for now.
Decompression is around 47 cycles per byte on these bundles files, which contain a variety of Unity asset data.
Now LZMA stats (level 9 16MB dictionary, default tuning options):
LZMA decompression was ~105 cycles/byte.
So LZHAM decompresses this data 2.2x faster. Its ratio is slightly lower, but this can be somewhat compensated for by enabling LZHAM's better parser and compressing offline (with a multicore desktop CPU). This helps a little: 4960935 bytes. By using more frequent Huff table updates (level 3 vs. the default 8) and extreme parsing, I get 4942383 compressed bytes, but decompression is ~18% slower. I'm going to graph all of this data next.
For reference, my iPhone 4's CPU is ~13.6x slower for compression and ~8.5x slower for decompression vs. my Core i7 3.3 GHz desktop CPU (comparing absolute wall time, no multithreading, same settings and file data, etc.).
Update: Here are the testing results after compressing & decompressing all of our uncompressed asset bundles on my iPhone 4. I limited LZHAM's compressor to a dictionary size of 8MB, less frequent table updating (table update speed of 12 vs the default 8), and normal parsing, which limited its ratio a bit vs. running it on desktop.
LZHAM is slower on a few files totaling ~.2% of the data (~320k out of 172MB), from there it rises to between 1.8x-4.8x faster. (Note I'm currently regenerating this graph so LZHAM's dictionary size matches LZMA's.)
1. Red=Speedup, Blue=LZMA compressed size, sorted by compressed size.

2. Red: Speedup, Blue: LZMA_comp_size/LZHAM_comp_size, sorted by speedup.

I combined together 3 of our larger Unity asset bundles together into a single .TAR file and here are the current results on my iPhone 4 (800 MHz A4 CPU - 512MB RAM):
LZHAM Compressed from 15209984 to 4999552 bytes
LZHAM Comp time: 112.771710, BPS: 134874.110168
LZHAM Decomp time: 0.895846, BPS: 16978346.767638
Decompression is around 47 cycles per byte on these bundles files, which contain a variety of Unity asset data.
Now LZMA stats (level 9 16MB dictionary, default tuning options):
LZMA compressed from 15209984 to 4726211 bytes
LZMA Comp time: 41.805776, BPS: 363824.942238
LZMA Decomp time: 1.993880, BPS: 7628334.723455LZMA decompression was ~105 cycles/byte.
So LZHAM decompresses this data 2.2x faster. Its ratio is slightly lower, but this can be somewhat compensated for by enabling LZHAM's better parser and compressing offline (with a multicore desktop CPU). This helps a little: 4960935 bytes. By using more frequent Huff table updates (level 3 vs. the default 8) and extreme parsing, I get 4942383 compressed bytes, but decompression is ~18% slower. I'm going to graph all of this data next.
For reference, my iPhone 4's CPU is ~13.6x slower for compression and ~8.5x slower for decompression vs. my Core i7 3.3 GHz desktop CPU (comparing absolute wall time, no multithreading, same settings and file data, etc.).
Update: Here are the testing results after compressing & decompressing all of our uncompressed asset bundles on my iPhone 4. I limited LZHAM's compressor to a dictionary size of 8MB, less frequent table updating (table update speed of 12 vs the default 8), and normal parsing, which limited its ratio a bit vs. running it on desktop.
LZHAM is slower on a few files totaling ~.2% of the data (~320k out of 172MB), from there it rises to between 1.8x-4.8x faster. (Note I'm currently regenerating this graph so LZHAM's dictionary size matches LZMA's.)
1. Red=Speedup, Blue=LZMA compressed size, sorted by compressed size.
2. Red: Speedup, Blue: LZMA_comp_size/LZHAM_comp_size, sorted by speedup.
Tuesday, January 20, 2015
LZHAM v1.0 vs. LZMA decomp. perf on a large corpus of files
LZHAM isn't always faster than LZMA. LZHAM has a more expensive startup cost (which I've reduced a bunch since the alpha but it's still there), and it must update several large Huffman tables at periodic intervals. The previous alpha versions had way too many Huff tables, which really dragged the codec down on some files. The new version now only has a handful of tables, I've reduced the default table update interval, and you can now fine tune the update interval. This graph was generated at update speed 20 (least # of updates/fastest).

(Thanks to John Brooks for giving me some feedback on this graph.)
Update: Here's a new, less noisy graph with the following differences:
- Filtered out all files with a LZMA comp ratio less than 2% (because we know LZMA totally sucks at these low ratios)
- Switched LZHAM into unbuffered mode, for a minor decompression speed boost.

To visualize where LZHAM is faster or slower, I ran a test app on a corpus of 21,702 files, all >= 1024 bytes (to reduce the sheer number of them) and timed how long LZHAM vs. LZMA took to decompress each file. This is a mix of game assets from various titles, the usual standard corpus files (calgary etc.), XML/JSON/binary JSON/source files, random WAV/BMP/TGA/JPG/MP3's, executables+DLL's from popular installs, etc. Just random stuff.
I tossed any results where LZMA expanded the data because in these cases LZMA is up to ~60x slower than LZHAM. LZHAM has special handling for uncompressed data, and LZMA does not, so it just bogs down really badly in these cases. There are still many cases in this graph where LZMA just bogs down terribly on nearly uncompressible files, LZHAM can win massively in this case because it chooses which 512k blocks to store uncompressed.
Here's the resulting graph showing LZMA's vs. LZHAM's decompression time on a 3.3 GHz Core i7, sorted by the LZMA's compressed file size. The blue line is the speedup, where less than 1.0 means LZMA was faster, and greater than 1.0 means LZHAM was faster.
The red line is the compressed file size on a log scale. This corpus has a ton of small (<4kb) files.
This graph shows than LZHAM v1.0 is pretty much always slower than LZMA if the compressed file size is <= ~2400 bytes. LZHAM can be only ~20% as fast in these cases. At around ~13k LZHAM is usually faster, and the greater the amount of compressed data the higher the likelihood that LZHAM is faster. You can estimate the threshold amount of original/source data if you know your data's average compression ratio.
Basically, LZHAM sucks on small blocks. I can make this somewhat better by reducing the startup cost, and optionally allowing the user to disable the huff table updating (or just slow it down even more). Another alternative is to have the compressor intelligently break up the input stream into a handful (or just 2) carefully chosen LZHAM blocks and issue a "update all huff tables now" command to the decompressor in between the block boundaries.
Basically, LZHAM sucks on small blocks. I can make this somewhat better by reducing the startup cost, and optionally allowing the user to disable the huff table updating (or just slow it down even more). Another alternative is to have the compressor intelligently break up the input stream into a handful (or just 2) carefully chosen LZHAM blocks and issue a "update all huff tables now" command to the decompressor in between the block boundaries.
Note all of my timings include the time LZHAM takes to allocate its work memory and initialize its internal data structures. The dictionary size for LZHAM was always 64MB in this test, while the dict. size for LZMA was tuned to be the first pow2 >= the source file size, so it's possible LZHAM is at a bit of a disadvantage here due to extra memory allocation costs relative to LZMA. I'm running another test (in LZHAM's unbuffered mode) to find out if this makes any difference.
(Thanks to John Brooks for giving me some feedback on this graph.)
Update: Here's a new, less noisy graph with the following differences:
- Filtered out all files with a LZMA comp ratio less than 2% (because we know LZMA totally sucks at these low ratios)
- Switched LZHAM into unbuffered mode, for a minor decompression speed boost.
Monday, January 19, 2015
Parallelized download+decomp performance of various codecs
I finished porting and testing LZHAM v1.0 on OSX today. Everything works, including multithreaded compression. I've also tuned the Huffman table updating options more. Next stop is iOS.
The graphs in the previous post show the summation of load_time+decomp_time at various download rates. For large amounts of data (not small blocks), it makes sense to decompress each buffer of compressed data as it becomes available (from the disk or network) using streaming decompression, instead of waiting for all the compressed data to be fully downloaded first.
The following graphs show uncompressed_size / MAX(load_time, decomp_time) at various download rates on ~166MB of uncompressed Unity iOS asset bundle data compressed as a single .TAR file with various codecs. (Of course, in case it's not obvious, I'm assuming everywhere here that the data has already been pre-compressed. I am not including compression times anywhere here.)
My brain is tired, but this should roughly approximate the total amount of time it would take to deliver the uncompressed data (ignoring the effects of buffering and other overheads). I'm also assuming it's a single large stream of compressed data and you're not doing something fancy like parallelizing decompression.
The version of LZHAM referenced in this post is v1.0, which I'll be releasing on github hopefully this week (not the old alpha on Google Code).
Note: I used the regular LZ4 compressor for these graphs, *not* LZ4-HC which compresses slightly better.
1. 3.3GHz CPU, X axis scale=281.63 megabytes/sec.

Graph 1: On fast CPU's, up until 13 MB/sec. download rates LZMA is the winner (because its ratio is highest), then up to 95MB/sec. LZHAM v1.0 switches to the winner (because its ratio is almost as high as LZMA but it decompresses more quickly - at these rates LZMA is just too slow to keep up with the download rate). After than, good old Deflate (miniz's decompressor) is best up until ~130MB/sec., then LZ4 takes over from there.
2. 3.3GHz CPU, X axis scale=2.35 megabytes/sec. (zoomed version of above)

Graph 2: A zoomed in version of the left of graph 1 showing more detail at the slower downloads speeds. Graph 2 shows that on fast CPU's and slow networks, LZMA is the clear winner because all that matters to the overall delivery time is compression ratio. LZHAM is close but loses because it has a slightly lower ratio (usually 1-4% lower) on this data. The other codecs just have too low a ratio to compete at these low network speeds.
3. VERY SLOW CPU, X axis scale=4.7 megabytes/sec.

Graph 3: A much slower CPU (simulated 1/12th the performance of my desktop CPU - just multiplied the decomp time by 12). This graph is zoomed in to show detail at low network speeds. LZMA is the winner up to ~1MB/sec., then it plateaus because it's too slow to keep up on this slow ass CPU. LZHAM can sustain up to 3MB/sec, then Deflate takes over. From there LZ4 will eventually take over as the winner at the higher network rates because Deflate eventually won't be able to keep up. At the very highest network rates it makes more sense to not even bother using compression at all, because the CPU won't be able to keep up, even with LZ4.
My 2 cents: The "best" codec to use (where "best" minimizes the amount of time the user needs to wait for the full download) depends on the client's CPU speed, the codec's compression ratio, and the download (or disk) rate. A smart content server (that doesn't give a crap about how much data it actually sends over the network) could choose the best codec to use depending on these factors.
To minimize content delivery (download) time on fast desktop CPU's, use something like LZMA or LZHAM. Single threaded LZMA doesn't scale beyond ~13MB/sec. on my CPU, where LZHAM will scale up to 95MB/sec. but has a slight download time penalty (around 1-4%) at the slower download rates.
On slow CPU's, LZMA plateaus very early. Beyond this download rate, LZHAM v1.0 is the winner, then Deflate followed by LZ4.
Of course, we do care about how much data must be downloaded, due to ISP caps, monthly rate plans, etc. In this scenario, we need to stick to using a high ratio codec like LZMA or LZHAM. LZMA doesn't scale well on slow CPU's, so we need something like LZHAM that has a similar ratio but scales more effectively.
To ultimately improve the current state of the art, we need a new codec with higher ratios than LZMA that doesn't run like a complete dog, use massive amounts of RAM, or require large #'s of cores to be practical. I don't know of any open source codecs that fit these requirements yet. Somebody needs to write one.
The graphs in the previous post show the summation of load_time+decomp_time at various download rates. For large amounts of data (not small blocks), it makes sense to decompress each buffer of compressed data as it becomes available (from the disk or network) using streaming decompression, instead of waiting for all the compressed data to be fully downloaded first.
The following graphs show uncompressed_size / MAX(load_time, decomp_time) at various download rates on ~166MB of uncompressed Unity iOS asset bundle data compressed as a single .TAR file with various codecs. (Of course, in case it's not obvious, I'm assuming everywhere here that the data has already been pre-compressed. I am not including compression times anywhere here.)
My brain is tired, but this should roughly approximate the total amount of time it would take to deliver the uncompressed data (ignoring the effects of buffering and other overheads). I'm also assuming it's a single large stream of compressed data and you're not doing something fancy like parallelizing decompression.
The version of LZHAM referenced in this post is v1.0, which I'll be releasing on github hopefully this week (not the old alpha on Google Code).
Note: I used the regular LZ4 compressor for these graphs, *not* LZ4-HC which compresses slightly better.
1. 3.3GHz CPU, X axis scale=281.63 megabytes/sec.
Graph 1: On fast CPU's, up until 13 MB/sec. download rates LZMA is the winner (because its ratio is highest), then up to 95MB/sec. LZHAM v1.0 switches to the winner (because its ratio is almost as high as LZMA but it decompresses more quickly - at these rates LZMA is just too slow to keep up with the download rate). After than, good old Deflate (miniz's decompressor) is best up until ~130MB/sec., then LZ4 takes over from there.
2. 3.3GHz CPU, X axis scale=2.35 megabytes/sec. (zoomed version of above)
Graph 2: A zoomed in version of the left of graph 1 showing more detail at the slower downloads speeds. Graph 2 shows that on fast CPU's and slow networks, LZMA is the clear winner because all that matters to the overall delivery time is compression ratio. LZHAM is close but loses because it has a slightly lower ratio (usually 1-4% lower) on this data. The other codecs just have too low a ratio to compete at these low network speeds.
3. VERY SLOW CPU, X axis scale=4.7 megabytes/sec.
Graph 3: A much slower CPU (simulated 1/12th the performance of my desktop CPU - just multiplied the decomp time by 12). This graph is zoomed in to show detail at low network speeds. LZMA is the winner up to ~1MB/sec., then it plateaus because it's too slow to keep up on this slow ass CPU. LZHAM can sustain up to 3MB/sec, then Deflate takes over. From there LZ4 will eventually take over as the winner at the higher network rates because Deflate eventually won't be able to keep up. At the very highest network rates it makes more sense to not even bother using compression at all, because the CPU won't be able to keep up, even with LZ4.
My 2 cents: The "best" codec to use (where "best" minimizes the amount of time the user needs to wait for the full download) depends on the client's CPU speed, the codec's compression ratio, and the download (or disk) rate. A smart content server (that doesn't give a crap about how much data it actually sends over the network) could choose the best codec to use depending on these factors.
To minimize content delivery (download) time on fast desktop CPU's, use something like LZMA or LZHAM. Single threaded LZMA doesn't scale beyond ~13MB/sec. on my CPU, where LZHAM will scale up to 95MB/sec. but has a slight download time penalty (around 1-4%) at the slower download rates.
On slow CPU's, LZMA plateaus very early. Beyond this download rate, LZHAM v1.0 is the winner, then Deflate followed by LZ4.
Of course, we do care about how much data must be downloaded, due to ISP caps, monthly rate plans, etc. In this scenario, we need to stick to using a high ratio codec like LZMA or LZHAM. LZMA doesn't scale well on slow CPU's, so we need something like LZHAM that has a similar ratio but scales more effectively.
To ultimately improve the current state of the art, we need a new codec with higher ratios than LZMA that doesn't run like a complete dog, use massive amounts of RAM, or require large #'s of cores to be practical. I don't know of any open source codecs that fit these requirements yet. Somebody needs to write one.
Sunday, January 18, 2015
Lossless codec performance on Unity asset bundle data
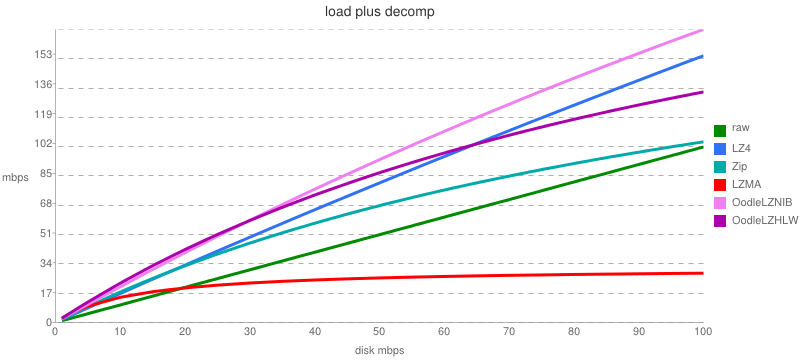
I really like Rad's way of graphing Oodle's (their lossless compression product) overall performance at different disk read (or download) rates. With graphs like this it's easy to determine at a glance the best codec to use given a particular CPU and download/disk rate, assuming your primary metric is just getting the original data into memory as quickly as possible.
As far as I can tell, the X axis is the disk read/download rate, and the Y axis is the effective content "delivery" rate assuming the client downloads the compressed data first and then decompresses it (load time+decomp time). We actually do these steps in parallel, which I'm going to graph next, but this is useful and simple to understand at a glance.
Inspired by this, here are some graphs hopefully computed in a similar manner comparing the effective performance of LZ4 (LZ4_decompress_safe()), miniz (my Deflate - close enough to zlib for this test, and pretty fast), LZMA, raw (no decompression), and LZHAM v1.0 (regular parsing/fastest Huffman table updating). I timed this on my Core i7 970 running at 3.3GHz according to CPUZ.
The first two graphs are for download rates up to 24 megabytes/sec, and the second three zoomed in graphs are for rates up to 2.4 megabytes/sec. I'm including these zoomed charts because a large number of our mobile customers can only download between .5 - 2 megabits/sec., and I don't care about disk read rates (we decompress as we download and store uncompressed bundle data on disk).
The 2nd and 4th graphs simulate a slower CPU, by just multiplying the decompression time by 5.0. These results are particularly interesting because the impact of a slower CPU significantly changes the relative rankings of each codec. (I need to make graphs on several popular iOS/Android devices, which would be most enlightening.)
Test Data: A full game's uncompressed iOS Unity asset bundles (a mix of MP3 audio, meshes, anims, PVRTC4 textures, and serialized objects), ~166MB total, compressed as a single .TAR file
1. FAST CPU UNZOOMED: 3.3 GHz - X axis scale: 24 megabytes/sec.

2. SLOW CPU UNZOOMED: ~.66 GHz - X axis scale: 24 megabytes/sec.

3. FAST CPU, 10x ZOOMED: 3.3 GHz - X axis scale: 2.4 megabytes/sec.

4. SLOW CPU, 10x ZOOMED: ~.66 GHz - X axis scale: 2.4 megabytes/sec.

Here's one more zoomed chart, 10x zoomed (2.4 megabytes/sec), simulating a very slow CPU (1/12th the perf. of my 3.3 GHz Core i7):
5. VERY SLOW CPU, 10x ZOOMED: ~.28 GHz - X axis scale: 2.4 megabytes/sec.

This last graph demonstrates why I've been sinking way too much time working on LZHAM:
- I don't care much about decompression at really fast disk speeds: LZ4 obviously fills that niche nicely. A smart content system will read from the slower medium (network, DVD, etc.), decompress and recompress to LZ4, and cache the resulting LZ4 data on a fast local device (HD/SSD).
- There's a lot of value in optimizing for low download speeds, and minimizing the overall amount of data downloaded (thanks to crappy ISP monthly download caps). We have real-life data showing many customers can download at only 500-2000 kbps, and this directly impacts how quickly they can get into our title on first run.
- Low end mobile CPU's are too slow to execute LZMA effectively. On slow CPU's even ancient Deflate can be a better choice vs. LZMA at high enough download rates.
So all I need to do now is actually test LZHAM v1.0 on a real A5 CPU and see if it performs as well as I hope it will.
{kind=link}
Inspired by this, here are some graphs hopefully computed in a similar manner comparing the effective performance of LZ4 (LZ4_decompress_safe()), miniz (my Deflate - close enough to zlib for this test, and pretty fast), LZMA, raw (no decompression), and LZHAM v1.0 (regular parsing/fastest Huffman table updating). I timed this on my Core i7 970 running at 3.3GHz according to CPUZ.
The first two graphs are for download rates up to 24 megabytes/sec, and the second three zoomed in graphs are for rates up to 2.4 megabytes/sec. I'm including these zoomed charts because a large number of our mobile customers can only download between .5 - 2 megabits/sec., and I don't care about disk read rates (we decompress as we download and store uncompressed bundle data on disk).
The 2nd and 4th graphs simulate a slower CPU, by just multiplying the decompression time by 5.0. These results are particularly interesting because the impact of a slower CPU significantly changes the relative rankings of each codec. (I need to make graphs on several popular iOS/Android devices, which would be most enlightening.)
Test Data: A full game's uncompressed iOS Unity asset bundles (a mix of MP3 audio, meshes, anims, PVRTC4 textures, and serialized objects), ~166MB total, compressed as a single .TAR file
1. FAST CPU UNZOOMED: 3.3 GHz - X axis scale: 24 megabytes/sec.
2. SLOW CPU UNZOOMED: ~.66 GHz - X axis scale: 24 megabytes/sec.
3. FAST CPU, 10x ZOOMED: 3.3 GHz - X axis scale: 2.4 megabytes/sec.
4. SLOW CPU, 10x ZOOMED: ~.66 GHz - X axis scale: 2.4 megabytes/sec.
Here's one more zoomed chart, 10x zoomed (2.4 megabytes/sec), simulating a very slow CPU (1/12th the perf. of my 3.3 GHz Core i7):
5. VERY SLOW CPU, 10x ZOOMED: ~.28 GHz - X axis scale: 2.4 megabytes/sec.
This last graph demonstrates why I've been sinking way too much time working on LZHAM:
- I don't care much about decompression at really fast disk speeds: LZ4 obviously fills that niche nicely. A smart content system will read from the slower medium (network, DVD, etc.), decompress and recompress to LZ4, and cache the resulting LZ4 data on a fast local device (HD/SSD).
- There's a lot of value in optimizing for low download speeds, and minimizing the overall amount of data downloaded (thanks to crappy ISP monthly download caps). We have real-life data showing many customers can download at only 500-2000 kbps, and this directly impacts how quickly they can get into our title on first run.
- Low end mobile CPU's are too slow to execute LZMA effectively. On slow CPU's even ancient Deflate can be a better choice vs. LZMA at high enough download rates.
So all I need to do now is actually test LZHAM v1.0 on a real A5 CPU and see if it performs as well as I hope it will.
LZHAM v1.0 vs. LZMA relative decompression rate on 262 Unity asset bundle files
Going to be honest here, graphing this stuff in a way that makes sense and is useful is tricky and time consuming. I really like the way Rad does it with their lossless data compression library, Oodle. I'm going to try making graphs like theirs.
Anyhow, here's a quick graph showing the relative speedup of LZHAM vs. LZMA on 262 uncompressed Unity asset bundle files (160MB total) from a single game. The bundle data consists of a mix of MP3 audio, Unity meshes, anims, PVRTC4 texture data, and lots of small misc. serialized Unity asset files.
The bundles are on the X axis (sorted by decompression speedup, from slowest to fastest), and the actual relative speedup is Y (higher is better for LZHAM). The blue line is the relative speedup (or slowdown on the first 5 files, each between 54-16612 bytes - these files are either very small or with pretty high ratios). Blue line at 1.0=same decompression rate as LZMA.
The red line represents each bundle's compression ratio relative to LZMA's. Above 1.0 means LZMA was better (smaller compressed file), and below 1.0 means LZHAM was better. LZHAM tracks LZMA's ratio pretty well, and equals or beats it in many cases. (I did put LZHAM's compressor into its slowest/best parsing mode to generate this data.)
I make no claims this is the best way to visualize a codec's perf relative to another, I'm just experimenting and trying to gain insight into LZHAM's actual performance relative to LZMA.
This was on a Core i7, x86 build, LZHAM options: -h12 -x (fastest/least frequent Hufftable updating, up to 4 solutions per node parsing).

Anyhow, here's a quick graph showing the relative speedup of LZHAM vs. LZMA on 262 uncompressed Unity asset bundle files (160MB total) from a single game. The bundle data consists of a mix of MP3 audio, Unity meshes, anims, PVRTC4 texture data, and lots of small misc. serialized Unity asset files.
The bundles are on the X axis (sorted by decompression speedup, from slowest to fastest), and the actual relative speedup is Y (higher is better for LZHAM). The blue line is the relative speedup (or slowdown on the first 5 files, each between 54-16612 bytes - these files are either very small or with pretty high ratios). Blue line at 1.0=same decompression rate as LZMA.
The red line represents each bundle's compression ratio relative to LZMA's. Above 1.0 means LZMA was better (smaller compressed file), and below 1.0 means LZHAM was better. LZHAM tracks LZMA's ratio pretty well, and equals or beats it in many cases. (I did put LZHAM's compressor into its slowest/best parsing mode to generate this data.)
I make no claims this is the best way to visualize a codec's perf relative to another, I'm just experimenting and trying to gain insight into LZHAM's actual performance relative to LZMA.
This was on a Core i7, x86 build, LZHAM options: -h12 -x (fastest/least frequent Hufftable updating, up to 4 solutions per node parsing).
Saturday, January 17, 2015
Good lossless codec API design
Lossless codec design and implementation seems to be somewhat of a black art. I've seen many potentially good lossless codecs come out with almost useless interfaces (or none at all). Here are some attributes I've seen of good codecs:
- If you want others to use your codec in their apps, don't just provide a single command line executable with a awkward as hell command line interface. Support static libraries and SO's/DLL's, otherwise it's not useful to a large number of potential customers no matter how cool your codec is.
- Minimum number of source files, preferably in all-C.
If you use C++, don't rely on a ton of 3rd party crap like boost, etc. It just needs to compile out of the box.
Related: Programmers are generally a lazy bunch and hate mucking around with build systems, make files, etc. Make it easy for others to build your stuff, or just copy & paste into your project. Programmers will gladly sacrifice some things (such as raw perf, features, format compatibility, etc. - see stb_image) if it's fast and trivial to plop your code into their project. Don't rely on a ton of weird macros that must be configured by a custom build system.
- Even if the codec is C++, provide the interface in pure C so the codec can be trivially interfaced to other languages.
- You must support Linux, because some customers only run Linux and they will refuse to use Wine to run your codec (even if it works fine).
- Must provide heap alloc callbacks, so the caller can redirect all allocations to their own system.
- Support a "compile as ANSI C" mode, so it's easy to get your codec minimally working on new platforms. The user can fill in the platform specific stuff (atomics, threading, etc.) later, if needed.
Related: If you use threads, support basic pthreads and don't use funky stuff like pthread spinlocks (because platforms like OSX don't support them). Basic pthreads is portable across many platforms (even Win32 with a library like pthreads-win32, but just natively support Win32 too because it's trivial).
- Don't assume you can go allocate a single huge 256MB+ block on the heap. On mobile platforms this isn't a hot idea. Allocate smaller blocks, or ideally just 1 block and manage the heap yourself, or don't use heaps.
- Streaming support, to minimize memory consumption on small devices. Very important in the mobile world.
- Expose a brutally simple API for memory to memory compression.
- Support a zlib-compatible API. It's a standard, everybody knows it, and it just works. If you support this API, it becomes almost trivial to plop your codec into other existing programs. This allows you to also leverage the existing body of zlib docs/knowledge.
- Support in-place memory to memory decompression, if you can, for use in very memory constrained environments.
- Single threaded performance is still important: Codecs which depend on using tons of cores (for either comp or decomp) to be practical aren't useful on many mobile devices.
- In many practical use cases, the user doesn't give a hoot about compression performance at all. They are compressing once and distributing the resulting compressed data many times, and only decompressing in their app. So expose optional parameters to allow the user to tune your codec's internal models to their data, like LZMA does. Don't worry about the extra time needed to compress, we have the cloud and 40+ core boxes.
- Provide a "reinit()" API for your codec, so the user can reuse all those expensive heap allocations you've made on the first init on subsequent blocks.
- Deal gracefully with already compressed, or incompressible data. Don't expand it, except by a tiny amount, and don't slow to a crawl. Related: don't fall over on very compressible data, or data containing repeated strings, etc.
- Communicate the intended use cases and assumptions up front:
Is it a super fast but low ratio codec that massively trades off ratio for speed?
Is it a symmetrical codec, i.e. is compression throughput roughly equal to decompression?
Is it a asymmetric codec, where (typically) compression time is longer than decompression time?
Is the codec useful on tiny or small blocks, or is it intended to be used on large solid blocks of data?
Does your codec require a zillion cores or massive amounts of RAM to be practical at all?
- Test and tune your codec on mobile and console devices. You'll be surprised at the dismally low performance available vs. even mid-range x86 devices. These are the platforms that benefit greatly from data compression systems, so by ignoring this you're locking out a lot of potential customers of your codec. The world is not just x86.
One some CPU's, stuff like int divides, variable length int shifts, and L2 cache misses are surprisingly expensive. On some platforms, CPU load hit stores can crush performance on seemingly decent looking code.
- Beware relying on floating point math in a lossless codec. Different compilers can do different things when optimizing FP math expressions, possibly resulting in compressed outputs which are compiler dependent.
- Test your codec to death on a wide variety of data, then test it again. Random failures are the kiss of death. If your codec is designed for game data then download a bunch of games on Steam, unpack the game data (using typically user provided unpack/modding tools) then add the data to your test corpus.
- Carefully communicate up front about forwards/backwards compatibility.
- Make sure your codec can be built using Emscripten for Javascript compatibility. Or just provide a native Javascript decoder.
- Make sure your compressor supports a 100% deterministic mode, so with the same source data and compressor settings you always get the exact same compressed data every time. This allows integrating your codec into build systems that intelligently check for file modifications.
- "Fuzz" test your codec by randomly flipping bits of compressed data, inserting/removing bits, etc. and make sure your decompressor will never crash or overwrite memory. If your decompressor can crash, make sure you document this so the caller can check the integrity of the compressed data before decompression. Consider providing two decompressors, one that is optimized for raw performance (but can crash), and another hardened decompressor that can't possibly crash on corrupted inputs.
Related: Try to design your bitstream format so the decompressor can detect corruption as quickly as possible. I've seen codecs fall into the "let's output 4GB+ of all-0's" mode on trivially corrupted inputs.
- Your decompressor shouldn't try to read beyond the end of valid input streams, even by a single byte. (In other words, when your decompressor in streaming mode says it needs more bytes to make forward progress, it better mean it.) Otherwise 100% zlib compatibility is out, and trying to read beyond the end makes it harder to use your decompressor on non-seekable input streams. (This can be a tricky requirement to implement in some decoder designs, which is why it's here.)
- Gracefully handle error conditions, especially out of memory conditions. Return a real error code, don't just terminate. Have enough error status codes so developers can easily debug why something went wrong in the field.
- Don't just focus on textual data. The Large Text Compression Benchmark is cool and all, but many customers don't have much text (if any) to distribute or store.
Off topic, but related: The pure Context Mixing based codecs are technically interesting, but every time I try them on real-life game data they are just insanely slow, use massive amounts of RAM, and aren't competitive at all ratio-wise against good old LZ based codecs like LZMA. I'm not claiming CM algorithms can't be improved, but I think the CM devs focus way too much on text (or bog standard formats like JPEG) and not enough on handling arbitrary "wild" binary data.
- Allow the user to optionally disable adler32/crc32/etc. checks during decompression, so they can do it themselves (or not). Computing checksums can be surprisingly expensive.
Also, think about your codec's strengths and weaknesses, and how it will be used in practice. It's doubtful that one codec will be good for all real-world use cases. Some example use cases I've seen from the video game world:
- If a game is displaying a static loading screen, the codec probably has access to almost the entire machine's CPU(s) and possibly a good chunk of temporary memory. The decompressor must be able to keep up with the data provider's (DVD/BlueRay/network) rate, otherwise it'll be the bottleneck. As long as the codec's consumption rate is greater or equal to the provider's data rate, it can use up a ton of CPU (because it won't be the pipeline's bottleneck). A high ratio, heavy CPU, potentially threaded codec is excellent in this case.
- If a game is streaming assets in the background during gameplay, the codec probably doesn't have a lot of CPU available. The decompressor should be optimized for low memory consumption, high performance, low CPU cache overhead, etc. It's fine if the ratio is lower than the best achievable, because streaming systems are tolerant of high latencies.
- Network packet compression: Typically requires a symmetrical, low startup overhead codec that can do a good enough job on small to tiny binary packets. Codecs that support static data models tuned specifically to a particular game's data packets are especially useful here.
- Content updates: Codecs which support delta compression (patching) are especially useful here. New assets generally resemble old ones.
Finally, in many games I've worked on or seen, the vast majority of distributed data falls into a few big buckets: Audio, textures, meshes, animations, executable, compiled shaders, video. The rest of the game's data (scripts, protodata, misc serialized objects) forms a long tail (lots of tiny files and a small percent of the total). It can pay off to support optimizations for these specific data types.
- If you want others to use your codec in their apps, don't just provide a single command line executable with a awkward as hell command line interface. Support static libraries and SO's/DLL's, otherwise it's not useful to a large number of potential customers no matter how cool your codec is.
- Minimum number of source files, preferably in all-C.
If you use C++, don't rely on a ton of 3rd party crap like boost, etc. It just needs to compile out of the box.
Related: Programmers are generally a lazy bunch and hate mucking around with build systems, make files, etc. Make it easy for others to build your stuff, or just copy & paste into your project. Programmers will gladly sacrifice some things (such as raw perf, features, format compatibility, etc. - see stb_image) if it's fast and trivial to plop your code into their project. Don't rely on a ton of weird macros that must be configured by a custom build system.
- Even if the codec is C++, provide the interface in pure C so the codec can be trivially interfaced to other languages.
- You must support Linux, because some customers only run Linux and they will refuse to use Wine to run your codec (even if it works fine).
- Must provide heap alloc callbacks, so the caller can redirect all allocations to their own system.
- Support a "compile as ANSI C" mode, so it's easy to get your codec minimally working on new platforms. The user can fill in the platform specific stuff (atomics, threading, etc.) later, if needed.
Related: If you use threads, support basic pthreads and don't use funky stuff like pthread spinlocks (because platforms like OSX don't support them). Basic pthreads is portable across many platforms (even Win32 with a library like pthreads-win32, but just natively support Win32 too because it's trivial).
- Don't assume you can go allocate a single huge 256MB+ block on the heap. On mobile platforms this isn't a hot idea. Allocate smaller blocks, or ideally just 1 block and manage the heap yourself, or don't use heaps.
- Streaming support, to minimize memory consumption on small devices. Very important in the mobile world.
- Expose a brutally simple API for memory to memory compression.
- Support a zlib-compatible API. It's a standard, everybody knows it, and it just works. If you support this API, it becomes almost trivial to plop your codec into other existing programs. This allows you to also leverage the existing body of zlib docs/knowledge.
- Support in-place memory to memory decompression, if you can, for use in very memory constrained environments.
- Single threaded performance is still important: Codecs which depend on using tons of cores (for either comp or decomp) to be practical aren't useful on many mobile devices.
- In many practical use cases, the user doesn't give a hoot about compression performance at all. They are compressing once and distributing the resulting compressed data many times, and only decompressing in their app. So expose optional parameters to allow the user to tune your codec's internal models to their data, like LZMA does. Don't worry about the extra time needed to compress, we have the cloud and 40+ core boxes.
- Provide a "reinit()" API for your codec, so the user can reuse all those expensive heap allocations you've made on the first init on subsequent blocks.
- Deal gracefully with already compressed, or incompressible data. Don't expand it, except by a tiny amount, and don't slow to a crawl. Related: don't fall over on very compressible data, or data containing repeated strings, etc.
- Communicate the intended use cases and assumptions up front:
Is it a super fast but low ratio codec that massively trades off ratio for speed?
Is it a symmetrical codec, i.e. is compression throughput roughly equal to decompression?
Is it a asymmetric codec, where (typically) compression time is longer than decompression time?
Is the codec useful on tiny or small blocks, or is it intended to be used on large solid blocks of data?
Does your codec require a zillion cores or massive amounts of RAM to be practical at all?
- Test and tune your codec on mobile and console devices. You'll be surprised at the dismally low performance available vs. even mid-range x86 devices. These are the platforms that benefit greatly from data compression systems, so by ignoring this you're locking out a lot of potential customers of your codec. The world is not just x86.
One some CPU's, stuff like int divides, variable length int shifts, and L2 cache misses are surprisingly expensive. On some platforms, CPU load hit stores can crush performance on seemingly decent looking code.
- Beware relying on floating point math in a lossless codec. Different compilers can do different things when optimizing FP math expressions, possibly resulting in compressed outputs which are compiler dependent.
- Test your codec to death on a wide variety of data, then test it again. Random failures are the kiss of death. If your codec is designed for game data then download a bunch of games on Steam, unpack the game data (using typically user provided unpack/modding tools) then add the data to your test corpus.
- Carefully communicate up front about forwards/backwards compatibility.
- Make sure your codec can be built using Emscripten for Javascript compatibility. Or just provide a native Javascript decoder.
- Make sure your compressor supports a 100% deterministic mode, so with the same source data and compressor settings you always get the exact same compressed data every time. This allows integrating your codec into build systems that intelligently check for file modifications.
- "Fuzz" test your codec by randomly flipping bits of compressed data, inserting/removing bits, etc. and make sure your decompressor will never crash or overwrite memory. If your decompressor can crash, make sure you document this so the caller can check the integrity of the compressed data before decompression. Consider providing two decompressors, one that is optimized for raw performance (but can crash), and another hardened decompressor that can't possibly crash on corrupted inputs.
Related: Try to design your bitstream format so the decompressor can detect corruption as quickly as possible. I've seen codecs fall into the "let's output 4GB+ of all-0's" mode on trivially corrupted inputs.
- Your decompressor shouldn't try to read beyond the end of valid input streams, even by a single byte. (In other words, when your decompressor in streaming mode says it needs more bytes to make forward progress, it better mean it.) Otherwise 100% zlib compatibility is out, and trying to read beyond the end makes it harder to use your decompressor on non-seekable input streams. (This can be a tricky requirement to implement in some decoder designs, which is why it's here.)
- Gracefully handle error conditions, especially out of memory conditions. Return a real error code, don't just terminate. Have enough error status codes so developers can easily debug why something went wrong in the field.
- Don't just focus on textual data. The Large Text Compression Benchmark is cool and all, but many customers don't have much text (if any) to distribute or store.
Off topic, but related: The pure Context Mixing based codecs are technically interesting, but every time I try them on real-life game data they are just insanely slow, use massive amounts of RAM, and aren't competitive at all ratio-wise against good old LZ based codecs like LZMA. I'm not claiming CM algorithms can't be improved, but I think the CM devs focus way too much on text (or bog standard formats like JPEG) and not enough on handling arbitrary "wild" binary data.
- Allow the user to optionally disable adler32/crc32/etc. checks during decompression, so they can do it themselves (or not). Computing checksums can be surprisingly expensive.
Also, think about your codec's strengths and weaknesses, and how it will be used in practice. It's doubtful that one codec will be good for all real-world use cases. Some example use cases I've seen from the video game world:
- If a game is displaying a static loading screen, the codec probably has access to almost the entire machine's CPU(s) and possibly a good chunk of temporary memory. The decompressor must be able to keep up with the data provider's (DVD/BlueRay/network) rate, otherwise it'll be the bottleneck. As long as the codec's consumption rate is greater or equal to the provider's data rate, it can use up a ton of CPU (because it won't be the pipeline's bottleneck). A high ratio, heavy CPU, potentially threaded codec is excellent in this case.
- If a game is streaming assets in the background during gameplay, the codec probably doesn't have a lot of CPU available. The decompressor should be optimized for low memory consumption, high performance, low CPU cache overhead, etc. It's fine if the ratio is lower than the best achievable, because streaming systems are tolerant of high latencies.
- Network packet compression: Typically requires a symmetrical, low startup overhead codec that can do a good enough job on small to tiny binary packets. Codecs that support static data models tuned specifically to a particular game's data packets are especially useful here.
- Content updates: Codecs which support delta compression (patching) are especially useful here. New assets generally resemble old ones.
Finally, in many games I've worked on or seen, the vast majority of distributed data falls into a few big buckets: Audio, textures, meshes, animations, executable, compiled shaders, video. The rest of the game's data (scripts, protodata, misc serialized objects) forms a long tail (lots of tiny files and a small percent of the total). It can pay off to support optimizations for these specific data types.
More LZHAM v1.0 progress
I'm currently seeing overall decompression speedups around 1.8x - 3.8x faster vs. previous LZHAM releases on Unity asset bundle files. On relatively incompressible files (like MP3's), it's around 2-2.3x faster, and 30-40% faster on enwik9. This is on a Core i7, I'll have statistics on iOS devices early next week.
I'm removing some experimental stuff in LZHAM that adds little to no real value:
- Got rid of all the Polar coding stuff and some misc. leftover params (like the cacheline modeling stuff)
- No more literal prediction, or delta literal predictions, for slightly faster decoding, lower memory usage, and faster initialization of the decompressor.
- Reduced is_match contexts from 768 to 12. The loss in ratio was a fraction of a percent (if any), but the decompressor can be initialized more quickly and the inner loop is slightly simplified because the prev/prev_prev decoded chars don't need to be tracked any more.
Just 2 main Huffman tables for literals/delta literals now, instead of 128 tables (!) like the previous releases. The tiny improvement in ratio (if any on many files) just didn't justify all the extra complexity. The decompressor's performance is now more stable (i.e. not so dependent on the data being compressed) and I don't need to worry about optimizing the initialization of a zillion Huff tables during the decoder's init.
I'm adding several optional, but extremely useful comp/decomp params:
// Controls tradeoff between ratio and decompression throughput. 0=default, or [1,LZHAM_MAX_TABLE_UPDATE_RATE], higher=faster but lower ratio.
lzham_uint32 m_table_update_rate;
m_table_update_rate is a higher level/simpler way of controlling these 2 optional params:
// Advanced settings - set to 0 if you don't care.
// def=64, typical range 12-128, controls the max interval between table updates, higher=longer interval between updates (faster decode/lower ratio)
lzham_uint32 m_table_max_update_interval;
// def=16, 8 or higher, scaled by 8, controls the slowing of the update update freq, higher=more rapid slowing (faster decode/lower ratio), 8=no slowing at all.
lzham_uint32 m_table_update_interval_slow_rate;
These parameters allow the user to tune the scheduling of the Huffman table updates. The out of the box defaults now cause much less frequent table updating than previous releases. The overall ratio change from the slowest (more frequent) to fastest setting is around 1%. The speed difference during decompression from the slowest to fastest setting is around 2-3x.
Next up: going to generate some CSV files to make some nice graphs, then the iOS and (eventually) Android ports.
I'm removing some experimental stuff in LZHAM that adds little to no real value:
- Got rid of all the Polar coding stuff and some misc. leftover params (like the cacheline modeling stuff)
- No more literal prediction, or delta literal predictions, for slightly faster decoding, lower memory usage, and faster initialization of the decompressor.
- Reduced is_match contexts from 768 to 12. The loss in ratio was a fraction of a percent (if any), but the decompressor can be initialized more quickly and the inner loop is slightly simplified because the prev/prev_prev decoded chars don't need to be tracked any more.
Just 2 main Huffman tables for literals/delta literals now, instead of 128 tables (!) like the previous releases. The tiny improvement in ratio (if any on many files) just didn't justify all the extra complexity. The decompressor's performance is now more stable (i.e. not so dependent on the data being compressed) and I don't need to worry about optimizing the initialization of a zillion Huff tables during the decoder's init.
I'm adding several optional, but extremely useful comp/decomp params:
// Controls tradeoff between ratio and decompression throughput. 0=default, or [1,LZHAM_MAX_TABLE_UPDATE_RATE], higher=faster but lower ratio.
lzham_uint32 m_table_update_rate;
m_table_update_rate is a higher level/simpler way of controlling these 2 optional params:
// Advanced settings - set to 0 if you don't care.
// def=64, typical range 12-128, controls the max interval between table updates, higher=longer interval between updates (faster decode/lower ratio)
lzham_uint32 m_table_max_update_interval;
// def=16, 8 or higher, scaled by 8, controls the slowing of the update update freq, higher=more rapid slowing (faster decode/lower ratio), 8=no slowing at all.
lzham_uint32 m_table_update_interval_slow_rate;
These parameters allow the user to tune the scheduling of the Huffman table updates. The out of the box defaults now cause much less frequent table updating than previous releases. The overall ratio change from the slowest (more frequent) to fastest setting is around 1%. The speed difference during decompression from the slowest to fastest setting is around 2-3x.
Next up: going to generate some CSV files to make some nice graphs, then the iOS and (eventually) Android ports.
Friday, January 16, 2015
LZHAM v1.0 progress
Ported to OSX, and exposed several new compression/decompression parameters to allow the user to configure some of the codec's inner workings: literal/delta_literal bitmasks (or number of literal/delta literal bits - less versatile but simpler), the Huff table max interval between updates, and the rate at which the Huff table update interval slows between updates. These settings are absolutely critical to the decompressor's performance, memory, and CPU cache utilization.
The very early results are promising: 25-30% faster decoding (Core i7) and much less memory usage (still determining) by just tuning the settings (less tables/slower updating), with relatively little impact on compression ratio. The ratio reduction is only a fraction of 1% on the few files I've tested. (Disclaimer: I've only just got this working. These results do make sense -- it takes a bunch of CPU to update the Huff decode tables.)
Also, by reducing the # of Huff tables the decompressor shouldn't bog down nearly so much on mostly incompressible data. The user can currently select between 1-64 tables (separately for literals and delta literals, for up to 128 total tables). The codec supports prediction orders between 0-2, with 2 programmable predictor bitmasks for literals/delta_literals. (I'm not really sure exposing separate masks for literals vs. delta literals is useful, but after my experience optimizing LZMA's options with Unity asset data I'm now leaning to just exposing all sorts of stuff and let the caller figure it out.)
I'm also going to expose dictionary position related bitmasks to feed into the various predictions, just like LZMA, because they are valuable on real-life game data.
Annoyingly, when I lower the compression ratio decompression can get dramatically faster. I believe this has to do with a different mix of the decode loop exercised by the lower ratio bitstream, but I'm not really sure yet (and I don't remember if I figured out why 3+ years ago). I'll be writing a guide on how to tune the various settings to speed up LZHAM's decompressor.
On the downside, the user has more knobs to turn to make max use of the codec.
The very early results are promising: 25-30% faster decoding (Core i7) and much less memory usage (still determining) by just tuning the settings (less tables/slower updating), with relatively little impact on compression ratio. The ratio reduction is only a fraction of 1% on the few files I've tested. (Disclaimer: I've only just got this working. These results do make sense -- it takes a bunch of CPU to update the Huff decode tables.)
Also, by reducing the # of Huff tables the decompressor shouldn't bog down nearly so much on mostly incompressible data. The user can currently select between 1-64 tables (separately for literals and delta literals, for up to 128 total tables). The codec supports prediction orders between 0-2, with 2 programmable predictor bitmasks for literals/delta_literals. (I'm not really sure exposing separate masks for literals vs. delta literals is useful, but after my experience optimizing LZMA's options with Unity asset data I'm now leaning to just exposing all sorts of stuff and let the caller figure it out.)
I'm also going to expose dictionary position related bitmasks to feed into the various predictions, just like LZMA, because they are valuable on real-life game data.
Annoyingly, when I lower the compression ratio decompression can get dramatically faster. I believe this has to do with a different mix of the decode loop exercised by the lower ratio bitstream, but I'm not really sure yet (and I don't remember if I figured out why 3+ years ago). I'll be writing a guide on how to tune the various settings to speed up LZHAM's decompressor.
Wednesday, January 14, 2015
More LZHAM notes
It's been a while since I've made any major changes to LZHAM (except for minor cmake related stuff). This was a codec I wrote over a few nights and weekends while I was also working my day job. I eventually had to let active dev on LZHAM go to sleep because I got "sidetracked" shipping Portal 2. The codec's alpha has already been successfully deployed in several products, such as Planetside 2 and Titanfall, which isn't bad for a few nights of R&D and implementation work.
I covered what I was thinking of doing with LZHAM in this blog post. I have more interest in improving it again. For the types of products I'm now working on, what matters a lot is the title's retention rate, from first starting the product to the customer actually getting into real gameplay. Slow downloads or updates, loading screens, etc. equals lost users. Lost users=lower monetization. We actually measure the retention rate of every aspect of this in the field. So things like background downloading, streaming, proper organization of asset data into Unity asset bundles, and of course good data compression matter massively to us.
Anyhow, some ideas for LZHAM decompression startup and throughput improvements which I can do pretty quickly:
- After much testing on our game data, I now realize I underestimated how useful the various LZMA settings are. Right now LZHAM always uses the upper 3 MSB's of the prev. two literals for literal/delta literal contexts. Allow the user to control all of this: which prev. literal(s) (if any), say up to 8 bytes back, and which bits from those literals, separately for each type of prediction (literals/delta literals).
- In my quest to get LZHAM's ratio up to be similar to LZMA I made several tradeoffs which can greatly impact decompression perf, especially on uncompressible data. Right now the codec must always init and manage 64*2 Huffman tables. Allow the user to reduce or even increase the # of tables.
- LZHAM was designed for "solid" compression, where you give the codec dozens to hundreds of MB's containing many assets, and you don't restart/reinit the codec in between assets. It's like a slow to start drag racer. So it can suck on small files.
I'm not honestly 100% sure what to do about this yet that won't kill decompression perf. The way LZHAM updates Huffman tables seems like an albatross here. Amortized over many MB's it typically works fine, but on small files they can't be updated (adapted) quickly enough. Less tables are probably good here.
I could just integrate something like miniz into the codec, and try using it on each internal compressor block and using whatever is better. But that seems horrible.
- The Huffman table update frequency needs to be better tuned. If I can't think of anything smarter, allow the user to control the update schedule.
Note if you are very serious about fast, high ratio compression and decompression, Rad's Oodle product is very good. Given what I know about it, it's the best (fastest, highest compression, and most scalable/portable) production class lossless codec I know of.
I covered what I was thinking of doing with LZHAM in this blog post. I have more interest in improving it again. For the types of products I'm now working on, what matters a lot is the title's retention rate, from first starting the product to the customer actually getting into real gameplay. Slow downloads or updates, loading screens, etc. equals lost users. Lost users=lower monetization. We actually measure the retention rate of every aspect of this in the field. So things like background downloading, streaming, proper organization of asset data into Unity asset bundles, and of course good data compression matter massively to us.
Anyhow, some ideas for LZHAM decompression startup and throughput improvements which I can do pretty quickly:
- After much testing on our game data, I now realize I underestimated how useful the various LZMA settings are. Right now LZHAM always uses the upper 3 MSB's of the prev. two literals for literal/delta literal contexts. Allow the user to control all of this: which prev. literal(s) (if any), say up to 8 bytes back, and which bits from those literals, separately for each type of prediction (literals/delta literals).
- In my quest to get LZHAM's ratio up to be similar to LZMA I made several tradeoffs which can greatly impact decompression perf, especially on uncompressible data. Right now the codec must always init and manage 64*2 Huffman tables. Allow the user to reduce or even increase the # of tables.
- LZHAM was designed for "solid" compression, where you give the codec dozens to hundreds of MB's containing many assets, and you don't restart/reinit the codec in between assets. It's like a slow to start drag racer. So it can suck on small files.
I'm not honestly 100% sure what to do about this yet that won't kill decompression perf. The way LZHAM updates Huffman tables seems like an albatross here. Amortized over many MB's it typically works fine, but on small files they can't be updated (adapted) quickly enough. Less tables are probably good here.
I could just integrate something like miniz into the codec, and try using it on each internal compressor block and using whatever is better. But that seems horrible.
- The Huffman table update frequency needs to be better tuned. If I can't think of anything smarter, allow the user to control the update schedule.
Note if you are very serious about fast, high ratio compression and decompression, Rad's Oodle product is very good. Given what I know about it, it's the best (fastest, highest compression, and most scalable/portable) production class lossless codec I know of.
Friday, January 9, 2015
Improved Unity asset bundle file compression
Download Times Matter
Sean Cooper, Ryan Inselmann and I have been building a custom lossless archiver designed specifically for Unity asset bundle files. The archiver itself uses several well-known techniques in the hardcore archiving/game repacking world. This post is mostly about how we've begun to tune the LZMA settings used by the archiver to be more effective on Unity asset bundle data. We'll cover the actual archiver in a later post.
LZMA has several knobs you can turn to potentially improve compression:
http://stackoverflow.com/questions/3057171/lzma-compression-settings-details
The LZHAM codec (my faster to decode alternative to LZMA) isn't easily tunable in the same way as LZMA yet, which is a flaw. I totally regret this because tuning these options works:
Total asset bundle asset data (iOS): 197,514,230
http://stackoverflow.com/questions/3057171/lzma-compression-settings-details
The LZHAM codec (my faster to decode alternative to LZMA) isn't easily tunable in the same way as LZMA yet, which is a flaw. I totally regret this because tuning these options works:
Total asset bundle asset data (iOS): 197,514,230
Unity's built-in compression: 91,692,327
Our archiver, un-tuned LZMA: 76,049,530Our archiver, tuned LZMA (48 option trials): 75,231,764
Our archiver, tuned LZMA (225 option trials): 74,154,817
LZ codecs with untunable models/settings are much less interesting to me now. (Yet one more thing to work on in LZHAM.)
Here are the optimal settings we've found for each of our Unity asset classes on iOS. So for example, textures are compressed using different LZMA options (3, 3, 3) vs. animation clips (1, 2, 2).
Best LZMA settings after trying all 225 options. (In case of ties the compressor just selects the lowest lc,lp,pb settings - I just placed a triply nested for() loop around calling LZMA and it chooses the first best as the "best".)
Class (id): lc lp pb
GameObject (1): 8 0 0
Light (108): 2 2 2
Animation (111): 8 2 2
MonoScript (115): 2 0 0
LineRenderer (120): 0 0 0
SphereCollider (135): 0 0 0
SkinnedMeshRenderer (137): 8 4 2
AssetBundle (142): 0 2 2
WindZone (182): 0 0 0
ParticleSystem (198): 0 2 3
ParticleSystemRenderer (199): 8 3 3
Camera (20): 0 2 2
Material (21): 3 0 1
SpriteRenderer (212): 0 0 0
MeshRenderer (23): 8 4 2
Texture2D (28): 8 2 3
MeshFilter (33): 8 4 1
Transform (4): 6 2 2
Mesh (43): 0 0 1
MeshCollider (64): 1 4 1
BoxCollider (65): 7 4 2
AnimationClip (74): 0 2 2
AudioSource (82): 0 0 0
AudioClip (83): 8 0 0
Avatar (90): 2 0 2
AnimatorController (91): 2 0 2
? (95): 7 4 1
TrailRenderer (96): 0 0 0
Tuesday, January 6, 2015
Utils/tools to help transition to OSX from Windows
I've developed software under Kubuntu and Windows for years now. I found adapting to Kubuntu from a Windows world to be amazingly easy (ignoring the random Linux driver installation headaches). After a few days mucking around with some keyboard shortcuts and relearning Bash and I was all set.
These days, the center of gravity in the mobile development world is OSX due to iOS's market share, so it's time I bit the bullet and dive into the Apple world.
I'll admit, transitioning to OSX has been mind numbingly painful at times. (Apple, why do you persist on using such a wonky keyboard layout? Where's my ctrl+left??! No alt+tab?? wtf? ARGH.) I mentioned this to Matt Pritchard, a long time OSX/iOS developer, and he passed along a list of OSX utilities and tools that can help make the transition easier for long-time Windows developers.
Monday, January 5, 2015
BonusXP's hybrid office arrangement
After my Valve experience I'm now deeply interested in how companies arrange and maintain the actual space their employees work in. The first thing I do when I enter a studio is look beyond the reception area and poke around to see how much importance and thought went into their actual workspace. This can tell you a lot about a company. Ignore the marketing and just observe.
BonusXP (makers of Monster Crew and Cave Mania, a growing indie game developer near Dallas in Allen, TX) used feedback from everyone at the studio to decide how their new office would be arranged. They decided on a hybrid mix of a low-density open plan surrounded by normal offices, with some key desk additions to cut down on visual distractions and give devs a better sense of control over their environment.
They also have a pretty sweet optional work from home on Friday policy.





BonusXP (makers of Monster Crew and Cave Mania, a growing indie game developer near Dallas in Allen, TX) used feedback from everyone at the studio to decide how their new office would be arranged. They decided on a hybrid mix of a low-density open plan surrounded by normal offices, with some key desk additions to cut down on visual distractions and give devs a better sense of control over their environment.
They also have a pretty sweet optional work from home on Friday policy.
Key things about this space that I see:
- Tidy: no rats nests, shabby furniture, or giant collections of 2000 nerf guns and action figures.
- Opaque glass dividers on each desk.
- Small offices with windows surrounding the open office area.
- Real desks with actual storage space.
- Low density and lots of space around each mini "pod" of desks.
- Blue color theme, which triggers a relaxing response.
Sunday, January 4, 2015
Robot Entertainment knows how to make open offices work better
There are precious few public pics available of Robot Entertainment's (The Orcs Must Die people near Dallas, TX - one of the post-Ensemble Studios companies) offices. This is a shame, because they've got a very smartly laid out space. (Update: Found more pics.)



.jpg)


The important elements:



Another major difference between Robot's offices verses the spaces of companies with dehumanizing, industrial scale open layouts is persistence and presence. At Robot's (and the old Ensemble Studios) offices, employees can bring in books, references, games, etc. and arrange them about their office in actual physical book cases and shelves. Sometimes Kindle doesn't cut it, especially for historical references. You can't practically do this at companies that attach wheels to your little desks and force you to play bumper cars every quarter.


For completeness, here's their lobby and meeting area:



Some impressions I get about this space by just looking at the pics: openness, welcoming, and team oriented.
- Discipline based "pod" organization and half partitions above eye height.
- Disruptive foot traffic and audio/visual noise mostly confined within a single pod.
- Pervasive availability of usable and visible whiteboards
- High ceilings
- No power cords ducktaped to the floor
- Lower density desk layout.
- Small desks with whiteboards encourages small meetings
And at this studio you get an entire Beer Garden in your offices. No high school lunch room cafeteria here!
Another major difference between Robot's offices verses the spaces of companies with dehumanizing, industrial scale open layouts is persistence and presence. At Robot's (and the old Ensemble Studios) offices, employees can bring in books, references, games, etc. and arrange them about their office in actual physical book cases and shelves. Sometimes Kindle doesn't cut it, especially for historical references. You can't practically do this at companies that attach wheels to your little desks and force you to play bumper cars every quarter.
For completeness, here's their lobby and meeting area:
Some impressions I get about this space by just looking at the pics: openness, welcoming, and team oriented.
Microsoft's vs. Valve's digs
I can't stand Microsoft's terrible "Modern" UI, but I'll give them props for having an actual Office Innovation Team that actually thinks about this stuff. (Total side note to the OIT people: Choose a different title, it's virtually impossible to search for it.)
From Pics of MS Building 4:



Contrast the above to this (from here):

Now where do you want to work?
You know, you can tell a lot about a company and its culture by just looking at photos of their offices.
From Pics of MS Building 4:
Contrast the above to this (from here):
{kind=link}
Now where do you want to work?
You know, you can tell a lot about a company and its culture by just looking at photos of their offices.
Bungie sure packs them in
For the record, my previous post wasn't intended to be focused on Valve in particular (but of course any mention of the big V will be latched on). I used V's offices as an example because it's the last open office environment I've experienced, and it sucked probably more than it should have due to a company culture that had utterly failed to adapt as the company scaled from a few dozen to hundreds of developers.
If I could go back in time, I would have inserted more examples from other companies. My major concern before I hit publish was pissing off the open office zealots who ignore the science.
Anyhow, Bungie's offices are literally right up the street from Valve's, so let's see what they look like. At least this space has high ceilings, so it probably doesn't feel as claustrophobic as V's and background noise doesn't propagate so much. Nonetheless, it still looks like a cattle pen to me:

If I could go back in time, I would have inserted more examples from other companies. My major concern before I hit publish was pissing off the open office zealots who ignore the science.
Anyhow, Bungie's offices are literally right up the street from Valve's, so let's see what they look like. At least this space has high ceilings, so it probably doesn't feel as claustrophobic as V's and background noise doesn't propagate so much. Nonetheless, it still looks like a cattle pen to me:
One forum comment (by IISANDERII) about this pic:
"Beginning to understand why they wanted to make players suffer and grind in Destiny. It was a silent revolt. I got a feeling it didn't look like this 15yrs ago."
I think very high ceilings are an important component of making open office spaces work at all, along with a company culture actually compatible with the open expression of ideas. Also, bad company culture can massively amplify the worst aspects of open office spaces.
The reality is, this is a very competitive industry, and it's difficult and expensive to hire skilled/experienced developers. The smart employers will realize that things like enforced industrial-sized cabal rooms and toxic peer-based stack ranking systems are boneheaded ideas and they'll come up with competitive alternatives to attract the best people. Ignoring the science and developer feedback to get X more hats live pronto is not smart.
Having experienced pretty much all possible layouts in my career, I would like to see a combination: A central room for say 15 people, surrounded by a large number of 1, 2, or 3 person offices, with at least 2-3 ways of leaving the central area. The small offices should resemble Ensemble's or Microsoft's: each with a door and a small vertical window near the door. Devs should be able to work where they want. Sometimes it makes sense to work together and collaborate, and sometimes you just need to concentrate. Usable whiteboards distributed throughout the space are critical.
Having experienced pretty much all possible layouts in my career, I would like to see a combination: A central room for say 15 people, surrounded by a large number of 1, 2, or 3 person offices, with at least 2-3 ways of leaving the central area. The small offices should resemble Ensemble's or Microsoft's: each with a door and a small vertical window near the door. Devs should be able to work where they want. Sometimes it makes sense to work together and collaborate, and sometimes you just need to concentrate. Usable whiteboards distributed throughout the space are critical.
Sheetrock, doors, whiteboards and glass are very cheap these days. These things are much less expensive to a company vs. the cost of a developer's time.
Thursday, January 1, 2015
Open Office Spaces and Cabal Rooms Suck
Caught this new article in the Washington Post:
Google got it wrong. The open-office trend is destroying the workplace.
Google got it wrong. The open-office trend is destroying the workplace.
In case it wasn't clear: I really dislike large open office spaces. (Not 2-3 person offices, but large industrial scale 20-100 person open office spaces of doom.) Valve's was absolutely the worst expression of the concept I've ever experienced. I can understand doing the open office thing for a while at a startup, where every dollar counts, but at an established company I just won't tolerate this craziness anymore. (See the scientific research below if you think I feel too strongly about this trend.)
As an engineer I can force myself to function in them, but only with large headphones on and a couple huge monitors to block visual noise. I do my best to mentally block out the constant audio/visual (and sometimes olfactory!) interruptions, but it's tough. It's not rocket science people: engineers cannot function at peak efficiency in Romper Room-like environments.

In case you've never seen or worked in one of these horrible office spaces before, here's a public shot showing a small fraction of the Dota 2 cabal room:
{kind=link}

I heard the desks got packed in so tightly that occasionally a person would lower or raise their desks and it would get caught against other nearby desks. One long-time Valve dev would try to make himself a little cubicle of sorts by parking himself into a corner with a bunch of huge monitors on his desk functioning as walls, kind of like this extreme example:

He also had little mirrors on the top of a couple monitors, so he could see what people were doing behind him. At first I thought he was a little eccentric, but I now understand.
After a while I realized "Cabal rooms" (Valve's parlance for a project-specific open office space) resembled panopticon prisons:

See that little cell in the back left there? That's your desk. Now concentrate and code!
Here's the list of issues I encountered while working in cabal (open office layout) rooms:
1. North Korea-like atmosphere of self-censorship:

Now at a place like my previous company, pretty much everyone is constantly trying to climb the stack rank ladders to get a good bonus, and everyone is trying to protect their perceived turf. Some particularly nasty devs will do everything they can to lead you down blind alleys, or just give you bad information or bogus feedback, to prevent you from doing something that could make you look good (or make something they claimed previously be perceived by the group as wrong or boneheaded).
Anyhow, in an environment like this, even simple conversations with other coworkers can be difficult, because all conversations are broadcasted into the room and you've got to be careful not to step on the toes of 10-20 other people at all times. Good luck with that.
2. Constant background noise: visual, auditory, olfactory, etc.
As an engineer, I do my best (highest value) work while in the "flow". Background noise raises the mental cost of getting into and staying in this state.
3. Bad physical cabal room placement: Don't put a cabal room next to the barber or day care rooms people (!).
4. Constant random/unstructured interruptions.
It's can be almost impossible to concentrate on (for example) massive restructurings of the Source1 graphics engine, or debugging the vogl GL debugger with UE4 while the devs next to you are talking about their gym lessons while the other dude is bragging about the new Porsche he just bought with the stock he sold back to the company.
5. Hyper-proximity to sick co-workers.
Walls make good neighbors, especially after they've caught a cold but feel pressured to be seen working so they come in anyway.
6. Noise spike in the afternoon in one cabal room, as everyone all the sudden decides to start chatting (usually about inane crap honestly) for 30-60 minutes. There's a feedback effect at work here, as everyone needs to chat louder to be heard, causing the background noise to go up, causing everyone to speak louder etc. Good luck if you're trying to concentrate on something.
7. Environmental issues: Temperature either too high or too low, lighting either too bright, too dark, or wrong color spectrum. Nobody is ever really happy with this arrangement except the locally optimizing bean counters.
8. Power issues or fire hazards due to extreme desk density.
9. Mixing electrical or mechanical engineers (who operate power tools, solder, destruct shit, etc.) next to developers trying their best to concentrate on code.
Related: Don't put smelly 3D printers etc. right next to where devs are trying to code.
10. Guest developers causing trouble:
Hyper-competitive graphics card vendors would watch the activity on our huge monitors and get pissed off when we emailed or chatted, even about inane crap, with other vendors.
Some guest developers treated coming to Valve like an excuse to party. We learned the hard way to always separate these devs into separate mini-cabal rooms.
11. No (or bad access to) white boards.
At Ensemble Studios (Microsoft), each 2-3 person office had a huge whiteboard on one wall. This was awesome for collaboration, planning, etc.
More articles on the nuttiness of open office layouts:
Open-plan offices make employees less productive, less happy, and more likely to get sickStudy: Open Offices Are Making Us All Sick
The Open Office Trap
http://www.sciencedirect.com/science/article/pii/S0272494413000340
Example of a GOOD office space:
Here's a quick summary of the scientific research (from The Open Office Trap):
"The open office was originally conceived by a team from Hamburg, Germany, in the nineteen-fifties, to facilitate communication and idea flow. But a growing body of evidence suggests that the open office undermines the very things that it was designed to achieve. In June, 1997, a large oil and gas company in western Canada asked a group of psychologists at the University of Calgary to monitor workers as they transitioned from a traditional office arrangement to an open one. The psychologists assessed the employees’ satisfaction with their surroundings, as well as their stress level, job performance, and interpersonal relationships before the transition, four weeks after the transition, and, finally, six months afterward. The employees suffered according to every measure: the new space was disruptive, stressful, and cumbersome, and, instead of feeling closer, coworkers felt distant, dissatisfied, and resentful. Productivity fell."
"In 2011, the organizational psychologist Matthew Davis reviewed more than a hundred studies about office environments. He found that, though open offices often fostered a symbolic sense of organizational mission, making employees feel like part of a more laid-back, innovative enterprise, they were damaging to the workers’ attention spans, productivity, creative thinking, and satisfaction. Compared with standard offices, employees experienced more uncontrolled interactions, higher levels of stress, and lower levels of concentration and motivation. When David Craig surveyed some thirty-eight thousand workers, he found that interruptions by colleagues were detrimental to productivity, and that the more senior the employee, the worse she fared."
"Psychologically, the repercussions of open offices are relatively straightforward. Physical barriers have been closely linked to psychological privacy, and a sense of privacy boosts job performance. Open offices also remove an element of control, which can lead to feelings of helplessness. In a 2005 study that looked at organizations ranging from a Midwest auto supplier to a Southwest telecom firm, researchers found that the ability to control the environment had a significant effect on team cohesion and satisfaction. When workers couldn’t change the way that things looked, adjust the lighting and temperature, or choose how to conduct meetings, spirits plummeted."Ultimately, I noticed the biggest proponents of open office spaces have no idea how programmers actually work, aren't up to date on the relevant science (if they are aware of it at all), and in many cases do their best to actually avoid working in the very open office spaces they enforce on everyone else.
Subscribe to:
Posts (Atom)