{kind=link}
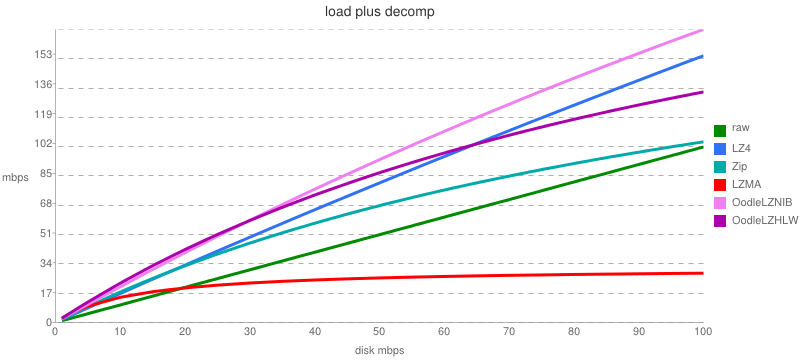
Inspired by this, here are some graphs hopefully computed in a similar manner comparing the effective performance of LZ4 (LZ4_decompress_safe()), miniz (my Deflate - close enough to zlib for this test, and pretty fast), LZMA, raw (no decompression), and LZHAM v1.0 (regular parsing/fastest Huffman table updating). I timed this on my Core i7 970 running at 3.3GHz according to CPUZ.
The first two graphs are for download rates up to 24 megabytes/sec, and the second three zoomed in graphs are for rates up to 2.4 megabytes/sec. I'm including these zoomed charts because a large number of our mobile customers can only download between .5 - 2 megabits/sec., and I don't care about disk read rates (we decompress as we download and store uncompressed bundle data on disk).
The 2nd and 4th graphs simulate a slower CPU, by just multiplying the decompression time by 5.0. These results are particularly interesting because the impact of a slower CPU significantly changes the relative rankings of each codec. (I need to make graphs on several popular iOS/Android devices, which would be most enlightening.)
Test Data: A full game's uncompressed iOS Unity asset bundles (a mix of MP3 audio, meshes, anims, PVRTC4 textures, and serialized objects), ~166MB total, compressed as a single .TAR file
1. FAST CPU UNZOOMED: 3.3 GHz - X axis scale: 24 megabytes/sec.

2. SLOW CPU UNZOOMED: ~.66 GHz - X axis scale: 24 megabytes/sec.

3. FAST CPU, 10x ZOOMED: 3.3 GHz - X axis scale: 2.4 megabytes/sec.

4. SLOW CPU, 10x ZOOMED: ~.66 GHz - X axis scale: 2.4 megabytes/sec.

Here's one more zoomed chart, 10x zoomed (2.4 megabytes/sec), simulating a very slow CPU (1/12th the perf. of my 3.3 GHz Core i7):
5. VERY SLOW CPU, 10x ZOOMED: ~.28 GHz - X axis scale: 2.4 megabytes/sec.

This last graph demonstrates why I've been sinking way too much time working on LZHAM:
- I don't care much about decompression at really fast disk speeds: LZ4 obviously fills that niche nicely. A smart content system will read from the slower medium (network, DVD, etc.), decompress and recompress to LZ4, and cache the resulting LZ4 data on a fast local device (HD/SSD).
- There's a lot of value in optimizing for low download speeds, and minimizing the overall amount of data downloaded (thanks to crappy ISP monthly download caps). We have real-life data showing many customers can download at only 500-2000 kbps, and this directly impacts how quickly they can get into our title on first run.
- Low end mobile CPU's are too slow to execute LZMA effectively. On slow CPU's even ancient Deflate can be a better choice vs. LZMA at high enough download rates.
So all I need to do now is actually test LZHAM v1.0 on a real A5 CPU and see if it performs as well as I hope it will.
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.